ИИ модели для генерации видео
Обновлено: 04.03.2026
Технологии машинного обучения позволяют автоматически генерировать видео по описанию. Генерация видео может применяться для бизнеса в следующих приложениях:
- маркетинг в Youtube и социальных сетях
- корпоративные новости
- обучение сотрудников
Примеры использования генерации видео для бизнеса с помощью искусственного интеллекта приведены ниже.
Пользователи, которые искали Генерация видео, потом также интересовались следующими продуктами:

См.также: Топ 10: ИИ платформы
- маркетинг в Youtube и социальных сетях
- корпоративные новости
- обучение сотрудников
Примеры использования генерации видео для бизнеса с помощью искусственного интеллекта приведены ниже.
Пользователи, которые искали Генерация видео, потом также интересовались следующими продуктами:
См.также: Топ 10: ИИ платформы
2025. В Adobe Firefly появилась возможность редактировать видео с помощью промптов

Компания Adobe обновила свой ИИ инструмент для работы с графикой Firefly, добавив в него видеоредактор, поддерживающий точное редактирование на основе текстовых подсказок. До сих пор Firefly поддерживал только генерацию на основе подсказок, поэтому, если какая-либо часть видео вас не устраивала, вам приходилось пересоздавать весь клип заново. В новом редакторе вы можете использовать текстовые подсказки для редактирования элементов видео, цветов и ракурсов камеры, а также появился новый режим просмотра временной шкалы, позволяющий легко настраивать кадры, звук и другие характеристики. Также появилась мозможность подключать новые сторонние модели для генерации изображений и видео, включая FLUX.2 и Topaz Astra от Black Forest Labs.
2025. Midjourney сделала модель для генерации видео

Компания Midjourney, известная своими генеративными ИИ-моделями для создания изображений, представила модель V1 для создания видеороликов, которая будет конкурировать OpenAI Sora, Adobe Firefly и Google Veo. Однако Midjourney традиционно делает ставку на творческое сообщество, а не на корпоративные или рекламные задачи. Как и основная модель Midjourney, V1 работает только через Discord. Пользователь может загрузить собственное изображение или использовать картинку, сгенерированную другим ИИ этой же платформы. Доступ к V1 открыт с базовой подписки $10, однако неограниченные генерации возможны только в тарифах Pro ($60) и Mega ($120) в медленном режиме. Видео можно продлевать до 21 секунды, а в настройках доступны варианты с автоматической или текстовой анимацией, а также выбор уровня движения.
2025. Google Veo 3 генерирует видео с диалогами

Google представил новейшую генеративную видеомодель Veo 3, которая теперь может автоматически добавлять диалоги, релевантную музыку и звуковые эффекты. Причем, ролики, генерируемые моделью выглядят невероятно реалистично и многие наблюдатели называют это следующим шагом в развитии генеративных видео-моделей. Если Google Veo 3 действительно генерирует видео такого качества (не один удачный вариант из тысячи), то уже можно создавать, например, рекламные ролики просто написав промпт. Также, в новой версии улучшено качество и физический рендеринг, добавлена возможность вывода в 4K, улучшено соблюдение промптов, что означает более точное соответствие результата вашим инструкциям.
2024. Модель Google Veo 2.0 научилась менять ракурсы видео
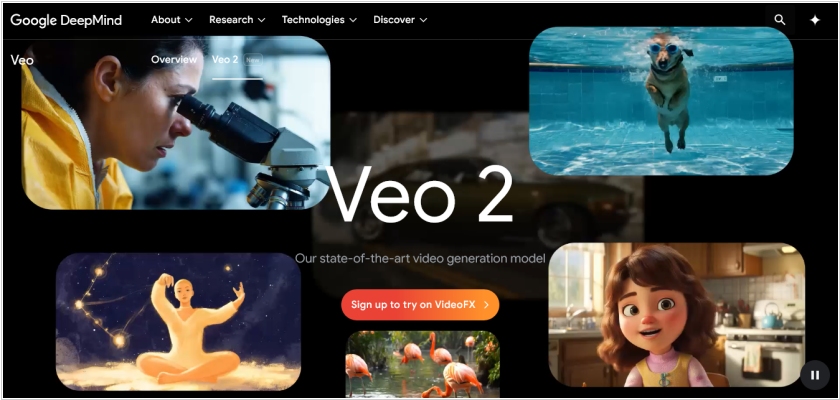
Сразу после релиза OpenAI Sora, Google обновил свою ИИ-модель для генерации видео - Veo 2.0. В новой версии Veo реализовано несколько действительно крутых новых функций, включая разрешение 4K, улучшенное управление камерой и гораздо более высокое общее качество по сравнению с предыдущей версией. По словам Google, Veo 2.0 - это огромный шаг вперед в детализации, реалистичности и уменьшении артефактов. Модель способна генерировать видео с высокоточными текстурами, естественными движениями и кинематографическим качеством по сравнению со своей предшественницей. Для режиссеров, маркетологов и создателей контента эти инструменты открывают возможности для создания более сложных сюжетов, генерируемых ИИ. Вместо того чтобы склеивать отдельные сцены, Veo теперь может создавать сложные, многоракурсные видео с помощью одного промпта.
2024. OpenAI представил модель для генерации видео Sora

Компания OpenAI представила видеогенератор Sora AI, который позволяет генерировать короткие видеоклипы по текстовым промптам. Однако с помощью дополнительных промптов можно в той или иной степени «ремиксировать» видео, а с помощью раскадровки можно объединить несколько промптов и создать переходы между роликами. В Sora видео ограничено разрешением от 480p до 1080p и длится не более 20 секунд. Для создания до 50 видеороликов в разрешении 480p и меньшее количество в разрешении 720p требуется подписка ChatGPT Plus за $20/мес. Пользователи подписки Pro (за $200/мес) смогут генерировать видео в разрешении 1080p, получают в 10 раз больше возможностей и смогут создавать более продолжительные видеоролики. Пользователи бесплатной версии ChatGPT - не могут создавать ролики.
2024. Meta представила ИИ-инструмент для создания видео со звуком

Meta анонсировала ИИ-генератор Movie Gen, который позволяет создавать видеоролики со звуком по текстовым запросам. Пользователю достаточно описать свой запрос словами, а потом при необходимости уточнить, какие изменения он хотел бы внести в полученное видео — например, в фон или цвета предметов, — и инструмент скорректирует нужную деталь. На видеоряд инструмент накладывает звуковое сопровождение в соответствии с его содержанием. Например, звук работающего двигателя при движении авто в кадре, шум водопада или грозы, а также музыкальные фрагменты. Озвучивать человеческую речь он пока не умеет.
2024. Adobe представила AI-инструмент, который превращает текст и изображения в видео

Компания Adobe представила новый инструмент на базе генеративного искусственного интеллекта, позволяющий создавать видеоклипы из статических изображений и описания. Он не только позволяет создавать видео, но и корректировать результат с помощью различных средств управления камерой, имитирующих изменение угла обзора, ее движение и расстояние, с которого ведется съемка. Также была продемонстрирована функция преобразования изображений в видео, которая может генерировать клипы на основе конкретных изображений. Новый инструмент расширит возможности видео-модели Adobe Firefly.
2024. Stability AI представила модель Stable Video 4D для генерации альтернативных ракурсов видео
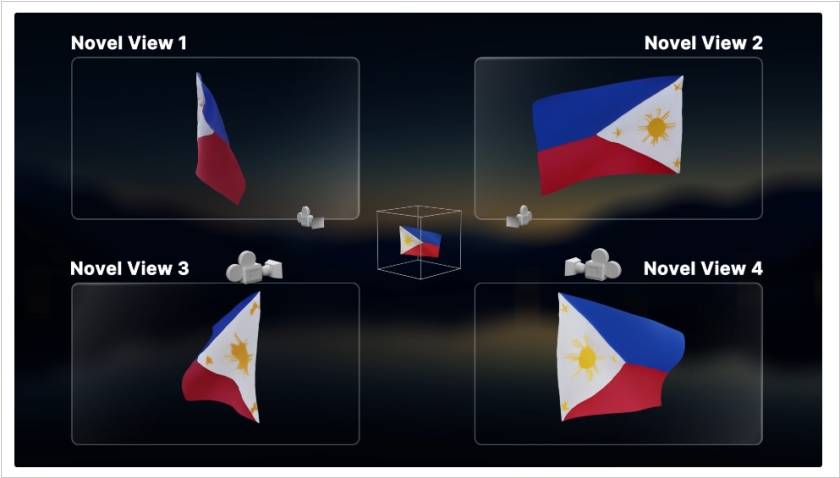
Stability AI показала модель машинного обучения Stable Video 4D, предназначенную для генерации новых ракурсов для видео. На входе нейросети надо передать видео, на основе которого она будет создавать новые ракурсы. После этого надо указать желаемые углы обзора. За один раз модель по умолчанию может сгенерировать до восьми ракурсов, но это количество можно изменить. Главная неприятность пока в том, что Stable Video 4D пока создаёт по пять кадров для каждого ракурса. В будущем разработчики планируют увеличить этот показатель. Нейросеть можно установить локально, она опубликовали на портале Hugging Face. Компаниям и частным лицам, которые будут использовать Stable Video 4D для коммерческой деятельности и зарабатывают больше миллиона долларов, надо запросить разрешение.
2024. Google добавил озвучку в свой ИИ-генератор видео Veo

Месяц назад Google Deepmind показал новую нейросеть для генерации видео Veo. Она может создавать короткие видео с разрешением 1080p в различных визуальных и кинематографических стилях на базе текстового описания и (опционально) изображений и видео-промптов. А теперь она еще и генерирует звуковую дорожку к видео. При чем, речь не просто о подборе саундтрека, подходящего по настроению к видео, а об осмысленном звуковом сопровождении. Например, если в кадре идет человек, будут слышны звуки его шагов, если пронеслась машина - (удаляющийся) шум мотора. Более того, модель может генерить речь персонажей (пока по текстовому описанию).
2024. OpenAI выпустил нейросеть Sora, которая превращает текст в реалистичные видео

OpenAI представила новую генаративную нейросеть под названием Sora, генерирующую реалистичные видео на основе текстового описания. Sora может создавать ролики продолжительностью до минуты, с высоким качеством изображения и четким соблюдением запроса пользователя. Она способна создавать сложные сцены с несколькими персонажами, динамичным поведением и детальной проработкой объектов и фона. Модель умеет понимать подсказки и знает, как ведут себя разные объекты в физическом мире. Sora доступна только для ограниченного количества пользователей, в частности, из-за опасений безопасности. Доступ имеют специалистов по исследованию уязвимостей для оценки потенциальных проблем и рисков.
2024. Google запустила нейросеть Lumiere для создания видео на основе текста

Google запустила открытую нейросеть для создания видео на основе текста. Сервис получил название Lumiere. По словам разработчиков, в отличие от конкурирующих проектов Lumiere создает видео от начала до конца в рамках одного процесса. Другие похожие сервисы сначала генерируют ключевые части кадров, после чего увеличивают их разрешение. Lumiere работает в нескольких режимах, например, производит преобразование текста в видео, конвертирует статические изображения в динамические, создаёт видеоролики в заданном стиле на основе образца, позволяет редактировать существующее видео по письменным подсказкам, анимирует определенные области статического изображения или редактирует видео фрагментарно — например, может изменить предмет гардероба на человеке.
2023. Stable Diffusion представила ИИ-сервис для создания видео по картинке или тексту

Предварительная версия модели Stable Video Diffusion с генеративным искусственным интеллектом доступна на GitHub. Stable Video Diffusion включает две модели: первая по одному изображению размером 576x1024 пикселей может сгенерировать 14 кадров, вторая — 25 кадров. Из них можно сделать видео с частотой кадров от трёх до 30 в секунду. Безопасность и качество нейросетей доработают на основе обратной связи от пользователей. Использовать модели в коммерческих целях пока запрещено — они доступны только для исследований. Можно также записаться в список ожидания для тестирования онлайн-сервиса, который генерирует видео по текстовому описанию.
2023. Представлена нейросеть Gen-2, которая создает видеоклипы по текстовому запросу пользователя

Компания Runway, которая участвовала в создании популярного генератора изображений Stable Diffusion, представила новую нейросеть Gen-2, которая предлагает создавать видео по текстовому запросу пользователя. Нейросеть на данный момент способна преобразовать текстовое описание в трехсекундный видеоклип, открывая широчайшие возможностей для создателей видеоконтента. Gen-2 не будет с самого начала открыта для широкого доступа из соображений безопасности. Вместо этого пользователи могут получить доступ к революционной технологии искусственного интеллекта через Discord, присоединившись к списку ожидания на сайте Runway.
2022. Google представил нейросеть для генерации видео по тексту Imagen Video

Буквально через несколько дней, после того, как Meta представила свою нейросеть для генерации видео Make-A-Video, Гугл объявил о разработке собственной аналогичной системы искусственного интеллекта Imagen Video, способной по языковому описанию генерировать видео с разрешением 1280×768 пикселей и частотой 24 кадра в секунду. Инструмент базируется на алгоритме Imagen, являющемся аналогом DALL-E 2 и Stable Diffusion. Генератор картинок использует большую предобученную языковую нейросеть и каскадную диффузную модель, и сочетает в себе «глубокий уровень понимания слов с беспрецедентной степенью фотореализма». Как поясняют исследователи Google, Imagen Video берет текстовое описание и создает 16-кадровый ролик с разрешением 24×48 пикселей и частотой 3 FPS. Затем система масштабирует и «предсказывает» дополнительные изображения.
2022. Meta представила нейросеть, которая по текстовым описаниям генерирует видео

Meta представила нейросеть Make-A-Video, которая по текстовым описаниям генерирует короткие ролики. Она работает на манер популярных нейросетей вроде DALL-E 2 и Midjourney. Нейросеть создаёт ролики без звука и не дольше пяти секунд, однако уже сейчас она может распознавать самые разные запросы. Нейросети пока нет даже в закрытом доступе, а все готовые ролики журналистам предоставила сама Meta. Поэтому пока до конца неясно, насколько на самом деле Make-A-Video хорошо понимает предложения и создаёт на их основе ролики. Пользователи могут подписаться на обновления.
2022. Нейросети Apple достаточно видео длиной 10 секунд, чтобы сделать реалистичный дипфейк

Компания Apple разработала нейронную сеть NeuMan, которая обучается на коротких видео и может генерировать «дипфейк»-видео. Для обучения нейросети достаточно видеоролика длиной 10 секунд, снятого движущейся камерой. Программа извлекает из видео изображение человека и окружающей среды. После этого NeuMan может синтезировать ролики, на которых тот же персонаж будет выполнять разные действия. Например, танцевать, кувыркаться или подпрыгивать. У нового видео меньшая резкость, но в целом они похожи на реальную съемку плохого качества. Основное назначение программы, как указывают разработчики, — это приложения для дополненной реальности. Они также отмечают, что для обучения нейросети используется две модели NeRF (нейрорадиального излучения): первая из них изучает человека, а вторая — фон. С помощью этих моделей нейросеть изучает грубую геометрию человека и сцены. А потом может воссоздать ее в новых формах.
2020. Сервис Synthesia создает видеообращения из произвольного текста
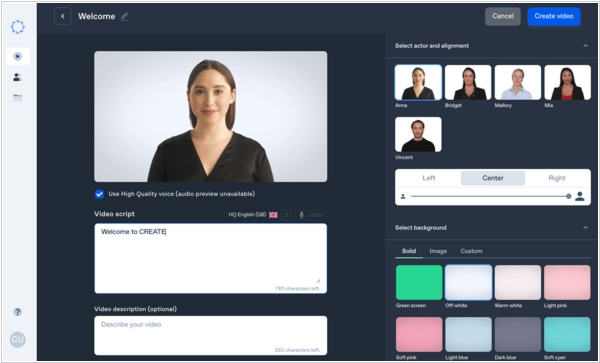
Онлайн платформа Synthesia позволяет преобразовать любой текст в видео, где его начитывает виртуальный персонаж. Чтобы воспользоваться новой функцией, введите свой текстовый сценарий и нажмите на кнопку «Генерировать». Видео будет готово через несколько минут, при стандартном объеме это займет 15 минут. Новая платформа доступна на 34 языках, в частности на русском. При стандартной генерации ваш текст читает актриса Анна, помимо нее можно выбрать из еще десяти персонажей. Создатели предлагают использовать новый сервис для организации рабочих презентаций, отправки видео-сообщений и других целей.